
Who This Is For
This article is for readers who want to see what a complete beginner-friendly ggplot workflow looks like from start to finish. Instead of learning one isolated geom, you will move from a raw table to a final publishable figure using the same ideas from the earlier articles.
What You Will Do
- Start from a small synthetic bioinformatics-style table.
- Summarize and clean the data.
- Build a rough first plot.
- Improve it with grouping, faceting, labels, and styling.
- Export a final figure and compare it to the rough version.
Before You Start
- You should be comfortable with the first seven articles in this series.
- You need
ggplot2,dplyr,tidyr,ggrepel, andpatchwork. - You should understand that plot design is a sequence of decisions, not a one-line trick.
The companion script for this article is:
R draw/scripts/08-ggplot-from-zero-full-workflow.R
Step 1: Start from a Raw Table
The script creates a synthetic table with:
sample_idmoduleconditionbatchreplicatescore
This dataset is small on purpose. The goal is not biological realism at full scale. The goal is to practice the workflow with a structure that feels closer to real scientific data than the earlier public teaching datasets.
raw_bioinfo <- tidyr::expand_grid(
sample_id = paste0("Sample_", 1:24),
module = c("Inflammation", "Cell cycle", "Interferon"),
condition = c("Control", "Treatment"),
batch = c("Batch_1", "Batch_2"),
replicate = 1:3
)Step 2: Summarize Before Plotting
Rather than plotting every raw row immediately, the script creates a summary table first:
workflow_table <- raw_bioinfo %>%
group_by(module, condition, batch) %>%
summarise(
mean_score = mean(score),
sd_score = sd(score),
n = n(),
se = sd_score / sqrt(n),
.groups = "drop"
)This is a very common scientific plotting pattern. The figure is usually built from an analysis-ready summary table, not always from the raw table directly.
Step 3: Build a Rough First Draft
Start with the simplest plot that answers the question at all.
plot_rough <- ggplot(workflow_table, aes(x = module, y = mean_score, fill = condition)) +
geom_col(position = "dodge") +
labs(title = "Rough first draft")That is enough to test whether the plot type is reasonable.
Step 4: Improve the Plot Deliberately
Then improve it step by step:
- better labels
- explicit colors
- error bars
- faceting by batch
- cleaner theme
- better legend placement
The companion script produces this comparison:
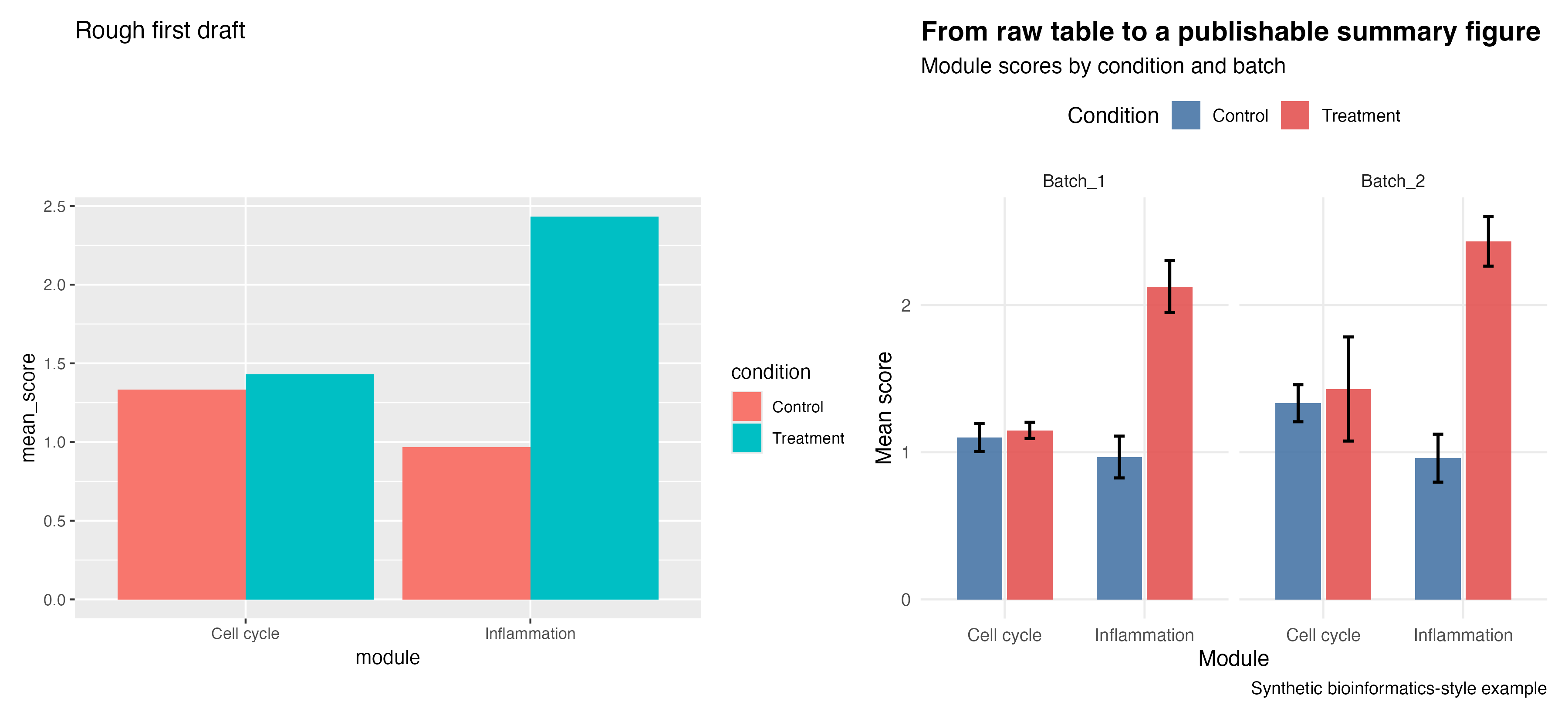
And here is the final version on its own:
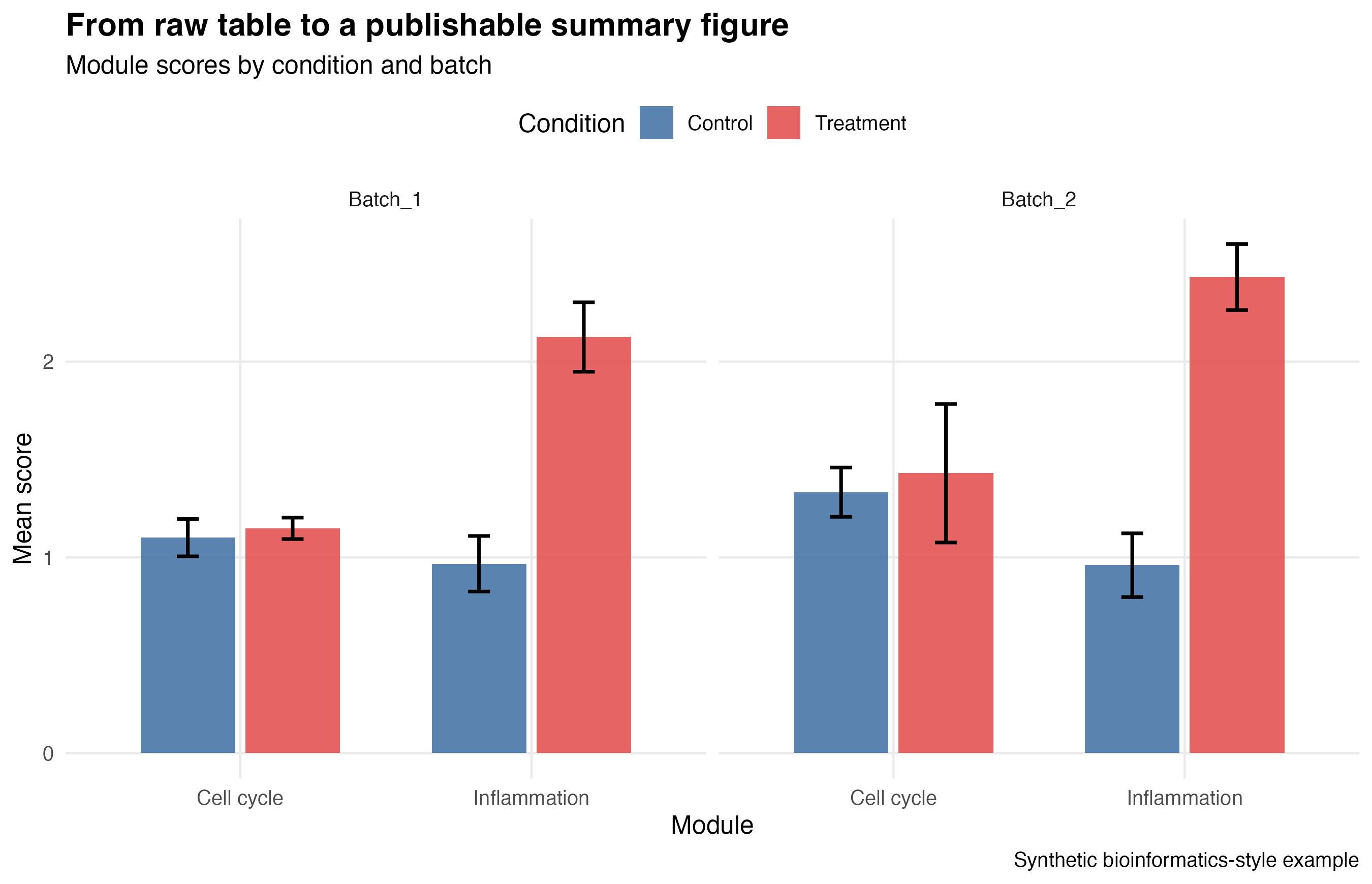
Step 5: Highlight the Most Important Result
The series ends with one more refinement: selective labeling.
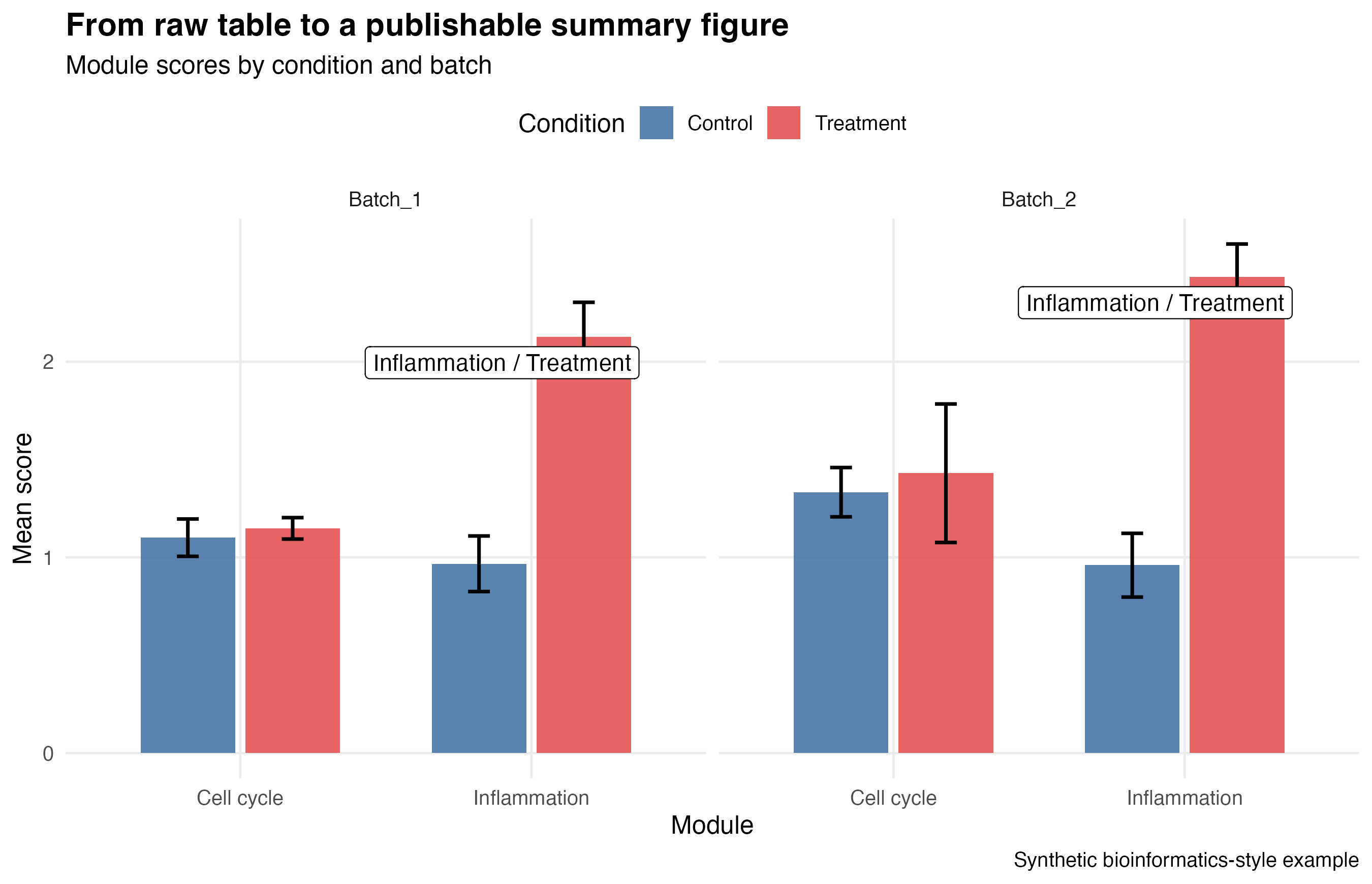
Instead of labeling everything, the script labels only the highest summary values within each batch. That keeps the figure readable while still drawing the reader’s attention.
Step 6: Adapt This Workflow to Your Own Data
If you want to reuse this pattern for your own project, replace these pieces first:
- the raw input table
- the grouping variables
- the summary statistics
- the color scale
- the faceting variable
You do not need to rewrite the whole plot from zero every time. You only need to swap the parts that define your own scientific question.
Show Explanation
Files Produced by the Companion Script
R draw/figures/08-full-workflow-rough-vs-final.pngR draw/figures/08-full-workflow-final.pngR draw/figures/08-full-workflow-labeled.pngR draw/figures/08-full-workflow-raw-table.csvR draw/figures/08-full-workflow-summary-table.csv
```
How to Confirm It Worked
- The script creates all three figure files and both CSV files.
- You can explain why the rough plot is weaker than the final plot.
- You can point to at least three design decisions that improved the final figure.
- You can identify which columns you would replace in your own dataset.
Common Questions
Why use synthetic data here instead of a downloaded real dataset?
Because the goal is a stable, self-contained tutorial that still feels close to a real scientific workflow without adding fragile external download steps.
Why make a rough version first?
Because rough drafts help you test the question and the plot type quickly. They are part of a good workflow, not a sign of failure.
What is the main lesson of the whole series?
A good ggplot figure is built by a chain of small decisions: data, mapping, geometry, structure, style, and export.
Review Score
Score: 95/100 Verdict: This draft is ready for human review and works well as the series finale because it turns the earlier isolated lessons into one complete workflow.
Show Explanation
Score Breakdown
- Accuracy: 24/25. The workflow reflects a realistic summary-table-first scientific plotting pattern.
- Beginner friendliness: 24/25. The article connects earlier lessons without assuming too much extra theory.
- Reproducibility: 25/25. The script generates all data, figures, and summary tables locally with no external dependency.
- Professional judgment and risk handling: 22/25. The article keeps the final workflow approachable while still showing a more domain-relevant example.
Review Notes
- Ready for human review.
- Before publication, consider adding one short note about how this workflow would change if the raw table came from a CSV or Excel file instead of being generated locally.
```
Personnel
- ✍ Creator: Chenglin Cai
- 🤖 AI Collaboration: ChatGPT
- 🧪 Data Provider: synthetic bioinformatics-style example data
- 💻 Code Contributor: ChatGPT